Das Bootstrapping Verfahren
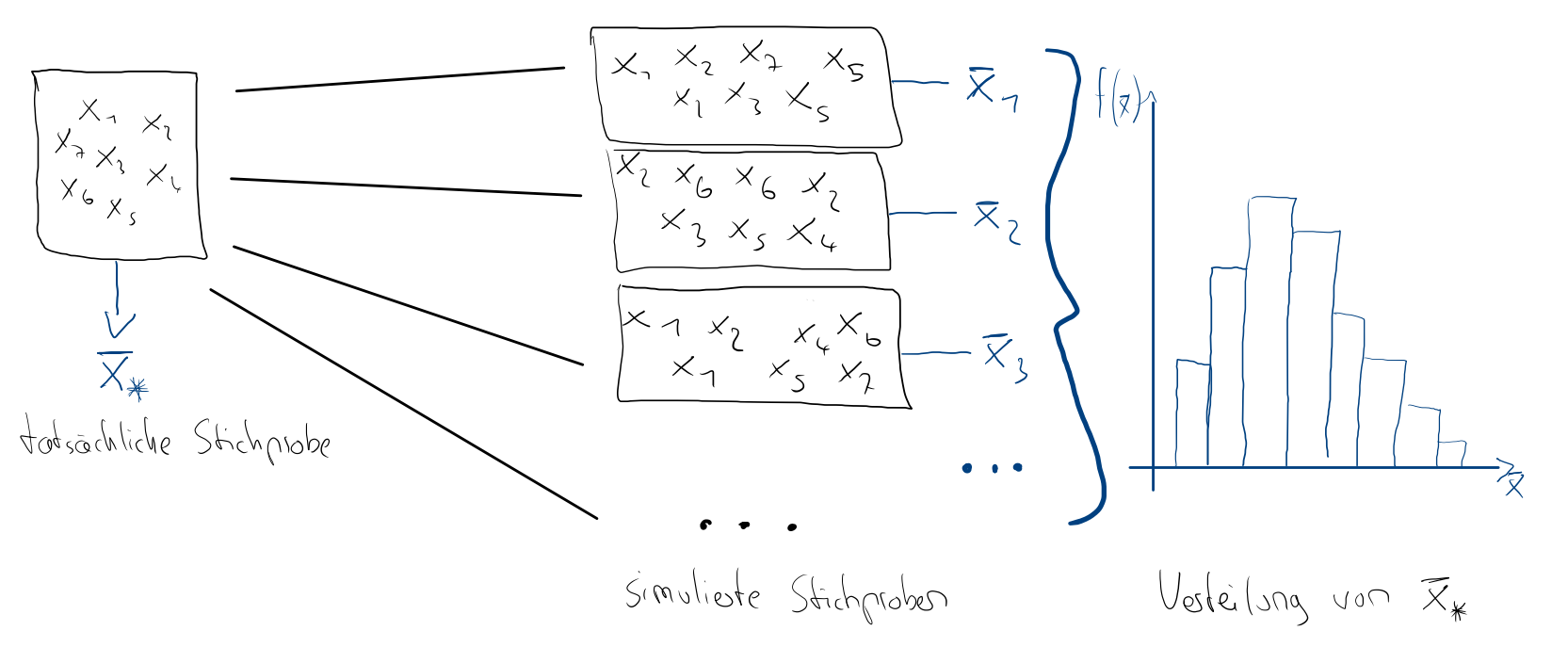
Das Ziel der Inferenzstatistik ist es, aus einer einzelnen Stichprobe $x_1, \dots, x_n$ die Stichproben-Verteilung eines Schätzers, wie dem Mittelwert $\bar{x}$ oder dem Median $x_{0.5}$, herzuleiten. Wenn die Stichproben-Verteilung eines Schätzers vorliegt kann damit der Wert des tatsächlichen unbekannten Populationsparameters eingegrenzt werden.
Für viele Schätzer kann deren Stichproben-Verteilung theoretisch hergeleitet werden. Neben der theoretischen Herangehensweise, gibt es auch eine intuitive empirische Methode, das Bootstrapping-Verfahren. Es basiert auf der Simulation von vielen Stichproben. Simulation bedeutet, dass die Stichproben nicht real erhoben, sondern alle aus der einzigen vorhanden Stichprobe erstellt werden.
Eine einzelne Bootstrapping-Stichprobe erhält man, indem aus der vorhanden Stichprobe der Größe $n$, genau $n$ Beobachtungen mit Zurücklegen zufällig gezogen werden. Das bedeutet, dass Beobachtungen mehrmals in der simulierten Stichprobe vorkommen können.
Beispiel
Nehmen Sie an, dass die Stichprobe die folgenden $n=7$ Werte enthält:
import pandas as pd
x = pd.Series([21, 13, 8, 14, 10, 12, 5])
x.mean()
Eine simulierte Bootstrapping-Stichprobe erhalten Sie, indem Sie aus der vorhandenen Stichprobe genau $n=7$ Werte mit Zurücklegen (replace=True) zufällig auswählen:
x.sample(n=len(x), replace=True)
Für jede simulierte Stichprobe wird daraufhin der zu interessierende Schätzwert berechnet. Um möglichst exakte Ergebnisse zu erhalten sollten mindestens $S \geq 5000$ Simulationen durchgeführt werden. Man erhält damit eine Annäherung an die tatsächliche Stichprobenverteilung des Schätzwerts:
Beispiel (Fortsetzung)
Wir erstellen eine Bootstrapping-Verteilung für den Stichproben-Mittelwert. Die Anzahl der Simulationen wird auf $S=10000$ festgelegt. Mit einer for Schleife wird die Simulation wiederholt. In jeder Simulation wird eine Bootstrapping-Stichprobe erstellt und deren Mittelwert berechnet.
x_means = []
S=10000
for i in range(S):
x_mean = x.sample(n=len(x), replace=True).mean()
x_means.append(x_mean)
Die Mittelwerte jeder Simulation werden in der Liste x_means abgespeichert. Die Liste enthält nun eine empirische Stichprobenverteilung des Mittelwerts. Nun können Sie sich die Verteilung des Stichproben-Mittelwertes beispielsweise in einem Histogramm ansehen:
#matplotlib inline
import seaborn as sns
sns.set()
sns.distplot(x_means, kde=False, bins=35)
Wie viele Mittelwerte liegen zwischen 9 und 11?
x_means = pd.Series(x_means)
x_means.between(9,11).mean()
- Lesen Sie den Datensatz ein
- Um eine homogene Stichprobe zu erhalten filtern Sie nach Bibliothekskunden die sich im Jahr 2010 registriert haben und auch noch im Jahr 2016 (als der Datensatz erstellt wurde) aktiv waren. Achtung: Die Spalte
'Circulation Active Year'wird standardmäßig als Text eingelesen. - Betrachten Sie die Variable
'Total Renewals'. Wie viele Verlängerungen wurden im Mittel durchgeführt? - Erstellen Sie, wie oben beschrieben, eine Stichprobenverteilung für den Mittelwert.
- Wie viel Prozent der Stichproben-Mittelwerte liegen zwischen 89 und 92 Verlängerungen?
- Wie groß müssen Sie das Intervall wählen, sodass 90% aller Bootstrapping-Mittelwerte darin liegen (Tip: Nutzen Sie die Funktion
pandas.Series.quantile)?